Parsing with PetitParser2
Simple, modular and flexible high-performance parsing framework.
Introduction
Introduction to PetitParser2
Migration from PetitParser
Parser Development
Scripting with Bounded Seas
Grammar
Context-Sensitive Grammar
Abstract-Syntax Tree
Full Parser
Comments
Optimizations
Optimization (Memoization)
PetitParser2 Internals
Star Lazy (In Progress)
Caches (In Progress)
Matching Tags (In Progress)
Context-Sensitivity (In Progress)
Manual Memoization
In the previous chapter we greatly improved the performance of our parser by calling optimize method.
The WebGrammar you see in the Pharo image already contains optimized version of the element rule.
In this chapter we suppose that element definition looks like defined in Extracting the Structure chapter, i.e. it looks like this:
WebGrammar>>element
^ (elOpen, elContent, elClose)
Let’s try the real sources then. The home page of we wikipedia, github, facebook and google can be parsed invoking this commands:
sources := PP2Sources current htmlSourcesAll.
parser := WebParser new optimize.
sources collect: [ :s |
parser parse: s.
]
Unfortunately, this still takes too much time (event with the automated optimizations). Can we do something, that the optimizations can’t? Usually, hard to say. It depends on the nature of a grammar and input to be parsed. In this case, we can improve the performance (we wouldn’t write this chapter otherwise).
Trace View
It is a good time to check the events morph of a debug result. Events morph shows timeline of parser invocations (dot) at a given position (x axis) in a given time (y axis). Inspect the result of the following command again and switch to Events view.
WebParser new optimize debug: input.
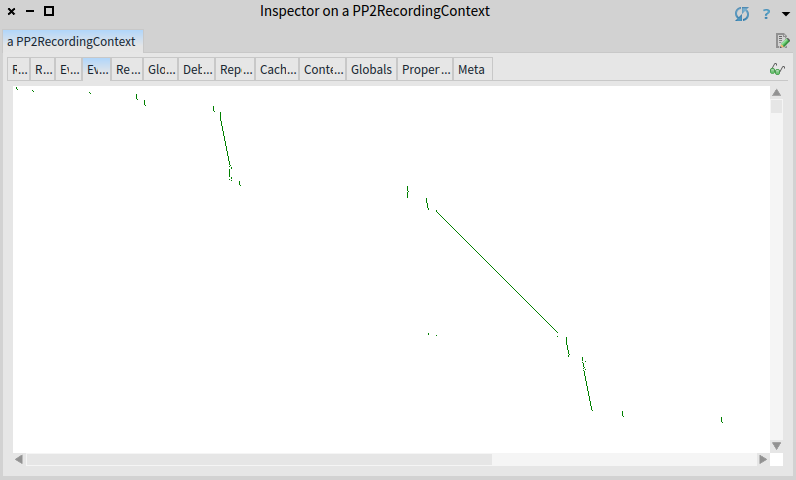
On the screenshot in there is only a part of the story (the part that fits into a single window). The whole story is that parsing progress fast towards the end of input (this is the good part), but suddenly parser jumps back to the beginning of input and starts again. Over and over again (this is the bad part).
For long inputs the Event tab shows only a beginning of the input and first few thousands of invocations.
Even though optimizations in PetitParser2 work reasonably well, not all of them can be applied automatically and must be done by poor humans. Luckily, there are tools to help those humans.
Searching for the cause
For the convenience of the visualization, we will use a compacted and simplified input.
compact := '
<!a>
<h>
<m foo>
<m e>
<b>
Lorem ipsum donor sit amet
</b>
</h>
'.
WebParser new optimize debug: compact.

In the events morph we see how does the parser backtrack, over and over.
We have to do a bit of detective work to figure out when and why.
Let us navigate through the parsing until the HTML body (represented by the b element in the compact input) is parsed:
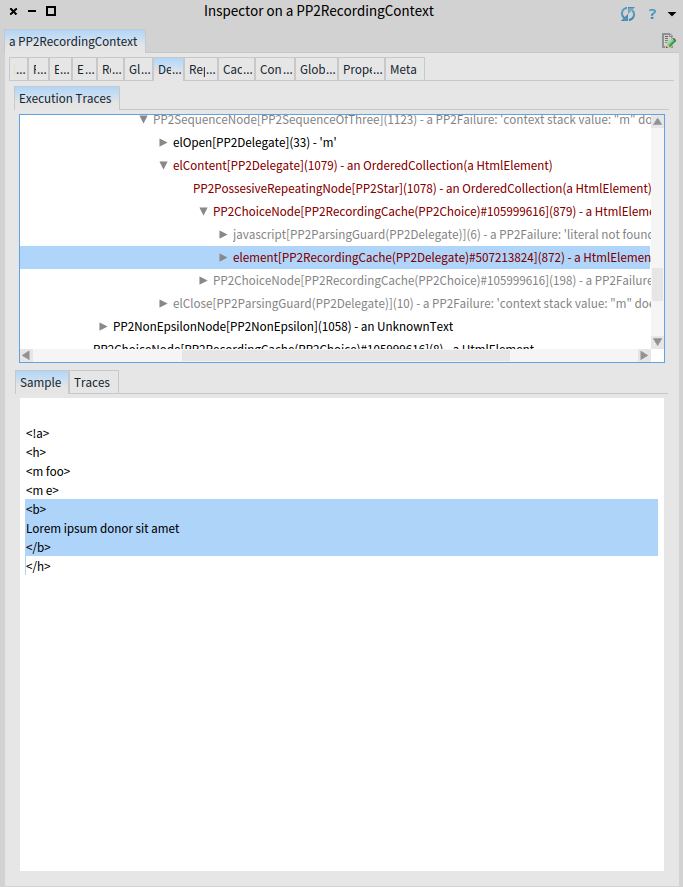
Now switch to the traces tab:
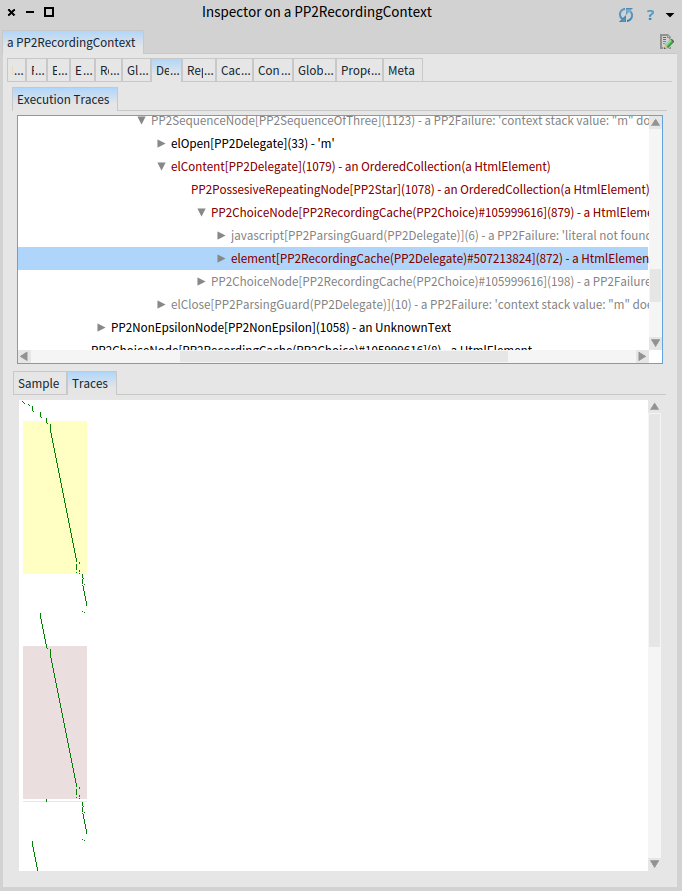
The yellow rectangle in the preivious figure highlights 872 underlying invocations of the element rule.
The dark red rectangle highlights another invocations of the same element rule that started at the same position.
And we see there are quite a few of them.
In general, one does not want to see repeating dark-red rectangles, and the more of them or the higher these dark-red rectangles are, the worse. It simply means redundant computations. Remember, each pixel on the y-axis is a parser invocation.
Why do these redundant invocations happen?
Because of the unclosed HTML meta elements (represented by m in the compact input).
The parser sees meta, starts an element, parses the content of meta, including the body element.
But it does not find the closing meta.
So it returns before the meta element, skips the meta part as a water and continues parsing.
This means it re-parses the body element again.
The more meta elements, the worse.
If you are watchful, you might have noticed a line behind a dark-red bar.
This line is created by automated cache, which immediately returns the result of a body element and prevents the whole execution.
But because it can remember only the last result, it can prevent only half of the executions.
Twice as fast is good, but we can do even better.
Fixing the Cause
Solution to this case is called memoization.
To suggest PetitParser2 to add memoization, add a memoize keyword to the element rule.
Memoization is a technique to remember all the results for all the positions (while caching remembered only the last result for the last position). Memoizations are costly, they should be applied carefully.
WebGrammar>>element
^ (elOpen, elContent, elClose)
memoize;
yourself
Let us check the result now:
WebParser new optimize debug: compact.
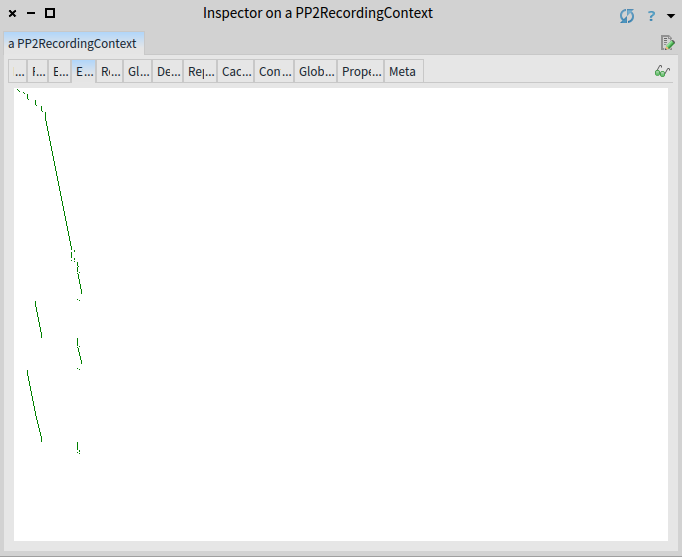
The shows what we want to see: no repeated invocations, no superfluous backtracking.
Parser still backtracks: it is because of the nature of the grammar.
Grammar is defined to speculate so it speculates.
We see two big backtrackings: one for each meta in the input, the html body itself is not re-parsed over and over again and the precious time is saved.
Pro tip: If you want to avoid backtracking of meta elements, you have to include syntax of meta into the grammar.
Parsing Real Sources
Finally, we can parse big sources as well, they should be parsed in a reasonable time now:
sources := PP2Sources current htmlSourcesAll.
parser := WebParser new optimize.
sources collect: [ :s |
parser parse: s.
]
Summary
Momoziation can turn exponential parsing-time complexity to a linear one. As PetitParser2 cannot apply memoization automatically, it provides tools to for users to identify which parsers should be memoized. By applying optimizations, we are able to parse real-world websites by a parser developed in a few hours.
Sources
The sources of this tutorial are part of the PetitParser2 package, you just need to install PetitParser2 or use Moose as described in the Introduction.