Parsing with PetitParser2
Simple, modular and flexible high-performance parsing framework.
Introduction
Introduction to PetitParser2
Migration from PetitParser
Parser Development
Scripting with Bounded Seas
Grammar
Context-Sensitive Grammar
Abstract-Syntax Tree
Full Parser
Comments
Optimizations
Optimization (Memoization)
PetitParser2 Internals
Star Lazy (In Progress)
Caches (In Progress)
Matching Tags (In Progress)
Context-Sensitivity (In Progress)
Comments
Code comments may contain scripts or other elements that are not part of the HTML document (they are just comments, right?).
Find a Bug
There is an error in WebParser that we have not found.
It extracts one extra HTML element, which is not part of the HTML document.
Inspect the following and switch to the tree view:
WebParser new parse: input.
There is a ‘‘<p>’’ element in the ‘‘<body>’’. But ‘‘<p>’’ is a part of a comment, it should not be included in the document structure.
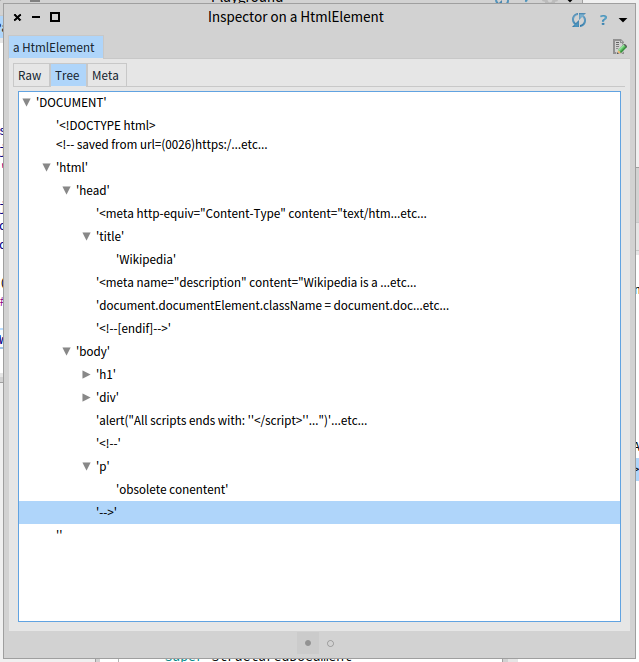
Check the our sample input:
PP2Sources current htmlSample.
There is an obsolete paragraph at the end of the file:
...
<script>alert("All scripts ends with: '</script>'...")</script>
<!-- <p>obsolete conentent</p> -->
...
First, we should fix the testStructuredDocument to cover this case:
WebParserTest>>testStructuredDocument
| html body |
super testStructuredDocument.
self assert: result name equals: 'DOCUMENT'.
html := result secondChild.
self assert: html name equals: 'html'.
self assert: html firstChild name equals: 'head'.
self assert: html secondChild name equals: 'body'.
body := html secondChild.
self assert: body children size equals: 4.
Where does the problem come from?
WebGrammar has no notion of a comment and handles a content of a comment as an ordinary html code.
In order to teach the grammar, we have to define comment first:
WebGrammar>>comment
^ '<!--' asPParser, any starLazy, '-->' asPParser
And now we can redefine text so that it takes comments into an account:
WebGrammar>>text
^ (comment / any) starLazy
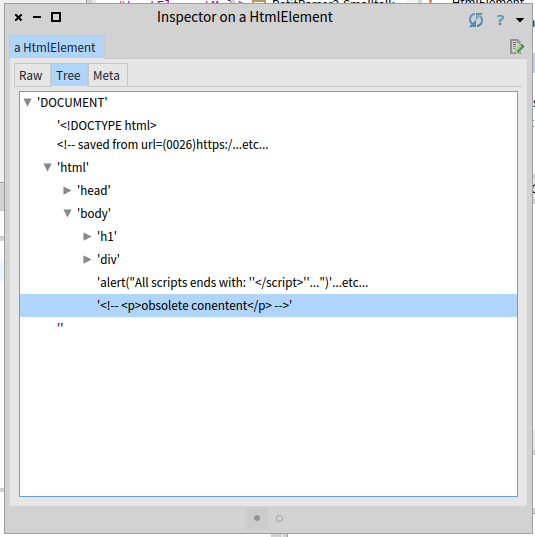
Now tests pass and AST looks good:
TODO(kurs): do we have starLazy chapter?
If you are interested in the details of the starLazy operator, check out the The starLazy Operator>starLazy.pillar chapter.
Summary
Parsers unaware of comments sooner or later return wrong results.
We fixed the issue by specifying the comment rule, which properly skips over comments in input.
Sources
The sources of this tutorial are part of the PetitParser2 package, you just need to install PetitParser2 or use Moose as described in the introduction.