Parsing with PetitParser2
Simple, modular and flexible high-performance parsing framework.
Introduction
Introduction to PetitParser2
Migration from PetitParser
Parser Development
Scripting with Bounded Seas
Grammar
Context-Sensitive Grammar
Abstract-Syntax Tree
Full Parser
Comments
Optimizations
Optimization (Memoization)
PetitParser2 Internals
Star Lazy (In Progress)
Caches (In Progress)
Matching Tags (In Progress)
Context-Sensitivity (In Progress)
Scripting with bounded seas: Extracting Javascript
In this chapter we extract javascript from html files using a Smalltalk playground.
Hands On
Open your playground and let’s start coding. First of all, we define what we want to parse:
source := PP2Sources current htmlSample.
The source very simplified (and slightly modified) version of Wikipedia>wikipedia.org and contains the following text:
<!DOCTYPE html>
<!-- saved from url=(0026)https://www.wikipedia.org/ -->
<html lang="mul" dir="ltr" class="js-enabled">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Wikipedia</title>
<meta name="description" content="Wikipedia is a free online encyclopedia, created and edited by volunteers around the world and hosted by the Wikimedia Foundation.">
<!--[if gt IE 7]-->
<script>document.documentElement.className = document.documentElement.className.replace( /(^|\s)no-js(\s|$)/, "$1js-enabled$2" );</script>
<!--[endif]-->
</head>
<body id="www-wikipedia-org">
<h1 class="central-textlogo" style="font-variant: small-caps" alt="WikipediA" title="Wikipedia">
<img src="./Wikipedia_files/Wikipedia_wordmark.png" srcset="portal/wikipedia.org/assets/img/Wikipedia_wordmark@1.5x.png 1.5x" width="174" height="30" alt="WikipediA" title="Wikipedia">
<strong id="js-localized-slogan" class="localized-slogan" style="visibility: visible;">The Free Encyclopedia</strong>
</h1>
<div id="mydiv">
Hi there!
</div>
<script>alert("All scripts ends with: '</script>'...")</script>
<!-- <p>obsolete conentent</p> -->
</body>
</html>
Second, we define javascript as a js rule:
js := '<script>' asPParser,
#any asPParser starLazy flatten,
'</script>' asPParser
==> #second.
The starLazy operator is a new feature of PetitParser2.
It repetitively invokes the given parser (any character in this case) until a string recognized by the following parser (</script> in this case) appears.
The starLazy operator is unique because you don’t need to specify the following parser, it is inferred automatically based on the grammar.
And with any change in the grammar, the starLazy updates itself.
If you want to define the same rule in the previous version of PetitParser, it would be:
'<script>' asParser,
(#any asParser starLazy: '</script>' asParser) flatten,
'</script>' asParser
==> #second
Let us try if the javascript rule can parse our source:
js parse: source.
The result is failure. Inspect the failure and switch to Debug View. Notice that <script> is expected at the beginning of a file, but input starts with <!DOCTYPE html>.
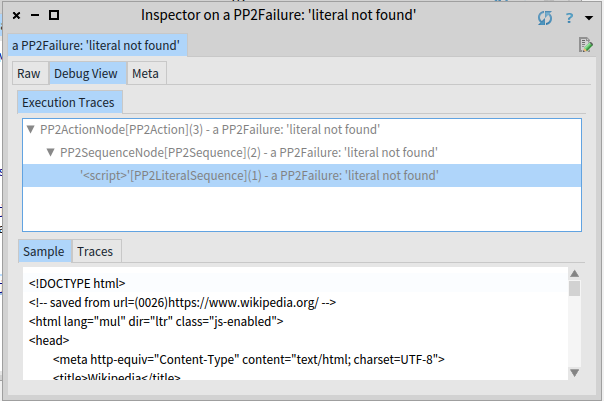
To fix it, create a new rule jsSea: a javascript island in a sea of an uninteresting water, using the sea operator:
jsSea := js sea ==> #second.
jsSea parse: source.
The sea operator does some magic and the result is not a failure!
Sea returns an array of three elements:
- before-water
- island and
- after-water
Island is the result of the javascript rule.
Before and after water contain the rest of an input (and today we are not interested in it) so we drop the water using js sea ==> #second, which returns only island.
Looks better, but we are missing some results!
This is because we never specified that there could be multiple occurrences of javascript (i.e. of jsSea rule).
We can easily add more jsSea rules by defining a document rule:
document := jsSea star.
The whole script looks like:
source := PP2Sources current htmlSample.
js := '<script>' asPParser,
#any asPParser starLazy flatten,
'</script>' asPParser
==> #second.
jsSea := js sea ==> #second.
document := jsSea star.
Now by calling document parse: source we extract both javascripts from the source, the result should look like:
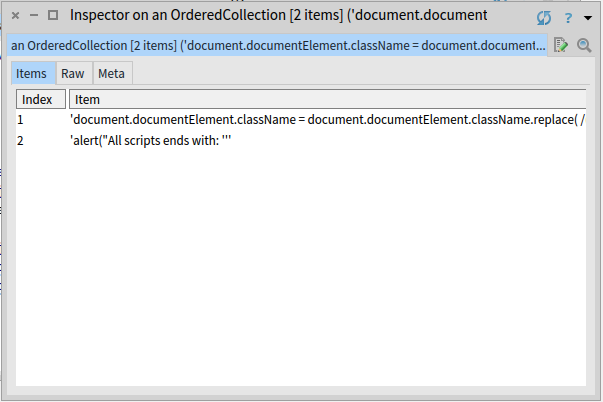
document.documentElement.className = document.documentElement.className.replace( /(^|\s)no-js(\s|$)/, "$1js-enabled$2" );alert("All scripts ends with: '
There is something fishy about the second result. The second javascript ended prematurely! It should look like this:
alert("All scripts ends with: '</script>'...")
It is ended prematurely, because the javascript rule js as we defined it does not know about strings.
Therefore, the javascript rule thinks that there is a closing of the script tag even though it is a part of the alert message string.
We can fix it by defining javascript strings and redefining the js rule:
any := #any asPParser.
jsString := $' asPParser, any starLazy, $' asPParser.
js := '<script>' asPParser,
((jsString / any) starLazy) flatten,
'</script>' asPParser
==> #second.
Great, everything works as expected!
document.documentElement.className = document.documentElement.className.replace( /(^|\s)no-js(\s|$)/, "$1js-enabled$2" );alert("All scripts ends with: '</script>'...")
If you think that what we did today can be done with a regular expression, you are absolutely right. Nevertheless, this is just a first step, PetitParser2 will boldly go where no regular expression has gone before.
Summary
We prototyped a parser to extract javascript from html files.
In the PetitParser2, there are sea and starLazy operators to help us skip an uninteresting input.