Parsing with PetitParser2
Simple, modular and flexible high-performance parsing framework.
Introduction
Introduction to PetitParser2
Migration from PetitParser
Parser Development
Scripting with Bounded Seas
Grammar
Context-Sensitive Grammar
Abstract-Syntax Tree
Full Parser
Comments
Optimizations
Optimization (Memoization)
PetitParser2 Internals
Star Lazy (In Progress)
Caches (In Progress)
Matching Tags (In Progress)
Context-Sensitivity (In Progress)
Optimizations Overview
When running the testStructuredDocument, you might have noticed that the performance is not good.
The WebGrammar you see in the Pharo image already contains optimized version of the element rule.
In this chapter we suppose that element definition looks like defined in Extracting the Structure chapter, i.e. it looks like this:
WebGrammar>>element
^ (elOpen, elContent, elClose)
Basic Analysis
It is actually terribly bad. Let us inspect in in detail:
input := PP2Sources current htmlSample.
WebParser new debug: input.
Report View
This will run the parser in a debug mode and collect a lot of useful information. Unfortunately, it also takes considerable amount of time so be patient. Once you get the result, inspect the Report tab (numbers might slightly differ in your case):
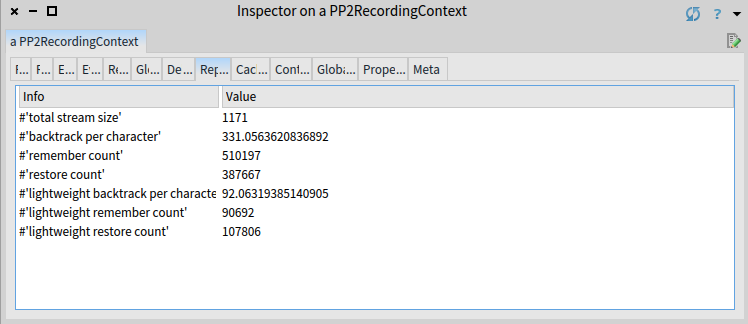
Based on the image, the total stream size is 1171 characters. The parser has remembered the full context 510197 times and restored 387667 times. This means that the full copy of the context (including the stack of opened elements, which we use to match open and close tags) has been created 510197 times and the context has been restored from this full copy (by doing another copy) 387667 times. This is in average 331 backtrackings per consumed character.
Some of the parsers didn’t copied full context. These are prefixed with lightweight. In the lightweight case, only the position is remembered and restored (which is much faster than the full copy of a stack). This happened in average 92 times per character.
Honestly, these numbers are brutal.
In ideal case, the number of full restores should be zero.
Full remember and restore is very expensive.
Very often only lightweight remember and restore happens, since many grammars are context-free, i.e. they do not use push, match and pop operators.
Regarding the lightweight backtracking, the average of lightweight backtracks per character should be below 1 (in ideal case). This typically happens for deterministic grammars, which do not do any (or only a little) speculations and do know exactly which alternative of a choice is the correct one.
Debug View
Our grammar is obviously not deterministic: it does lots of speculations. Why are the numbers so bad in our case? Inspect in more detail how this was happening, use the Debug view:
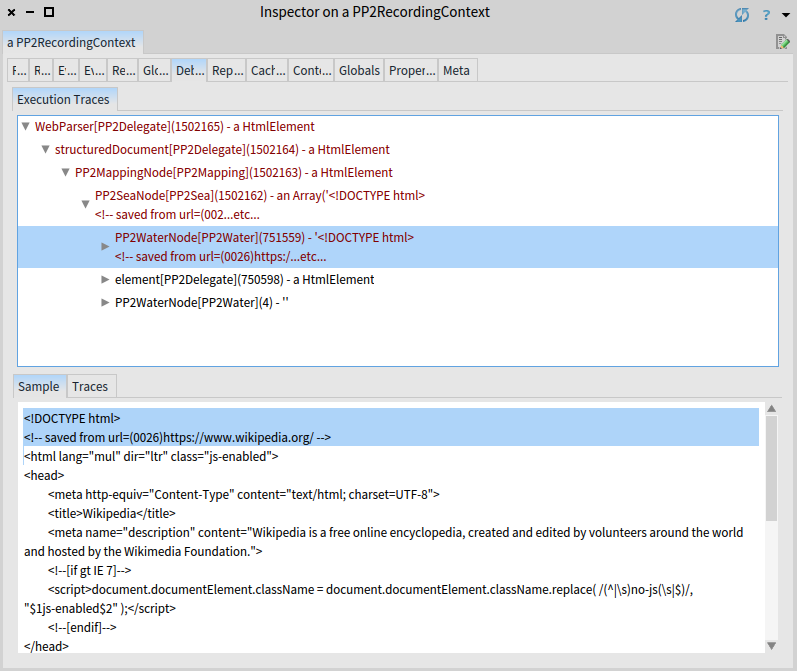
The view in shows that 1502165 parsers were invoked to consume the input. Most of it (751559 invocations) happened when parsing first two lines of the input — the before water of the sea.
Numbers are too high for a short input.
Such a bad performance is caused by the fact that bounded seas have to verify at every position if the next parser (i.e. the parser that will be invoked after the sea) will succeed.
If the next parser happens to be another sea (as in the case of WebGrammar), the number of invocations grows really fast (exponentially in fact).
We see that the element rule took approximately one half of the invocations (750598).
Majority of 751559 invocations of before water were spent by testing for element.
Another glimpse of ineffectiveness can be seen in the elOpen rule.
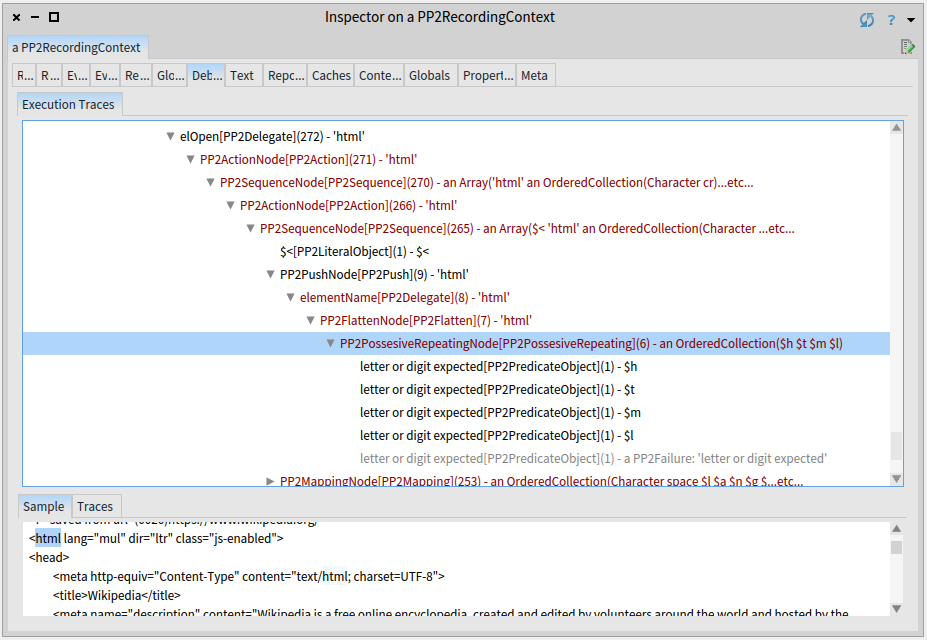
The whole <html lang="html" dir="ltr" class="js-enabled"> is parsed by invoking 272 parsers.
This is quite a lot for a line with 55 characters.
One of the reasons is how are the identifiers (elementName) parsed.
You can see that when recognizing the html text, 8 different parsers are invoked; for each letter one and some extra boilerplate parsers (flattening, possessive repeating,…).
The optimize method
PetitParser2 comes with an automated optimizations that are able to reduce most of the unnecessary overhead. Let it give a try:
WebParser new optimize debug: input.
The report looks much better now:
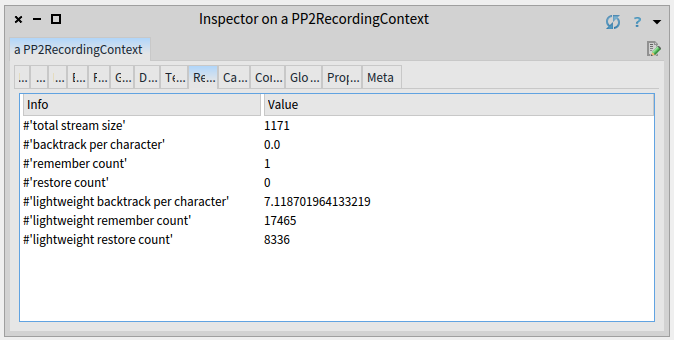
Only one full remember, and only 7 lightweight backtracks per character. This is reasonably good for a grammar with bounded seas.
Because of the nature of bounded seas and nature of PetitParser2, we do not recommend to parse grammars with more complicated bounded seas without optimizations.
Optimization in Detail
Let us inspect some of the optimizations that happened. We switch to Debug view:
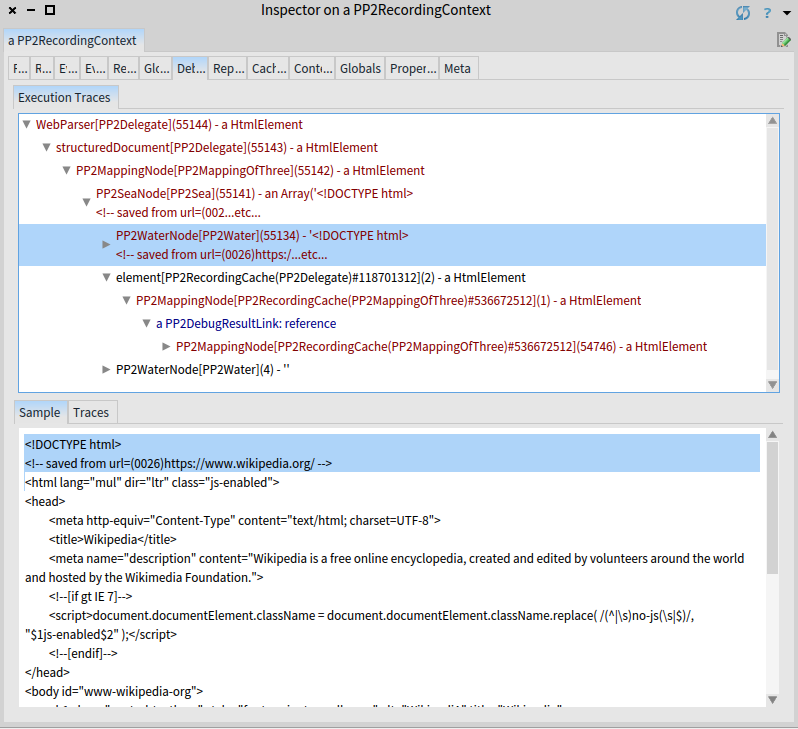
The figure shows the total number of invoked parsers is 55144, roughly 30x less. Most of the parsers are still invoked in the before-water of the initial sea and it is roughly 10x better now. The following island and after-water are parsed using only 2 and 4 parser invocations respectively.
Caches
The main reason of reduced invocations is caching.
Under the element rule in the debug view of an optimized parsing is a mapping node.
The mapping node returns the complete HTML element just in one single invocation.
The fact that the result has been cached is visualized via the result reference (represented by PP2DebugResultLink: reference).
The reference indicates that at the time of invocation the result has already been computed during some previous invocation. The parser remembered the result and returned the remembered without invoking the parser again.
There is another mapping node as a child of the reference with 54746 underlying invocations. But as mentioned these have happened before and mapping node shows them just for the convenience.
More about caches can be found in the caching chapter.
Specializations
Another optimizations applied by PetitParser2 are specializations. See the opening of an html element: <html lang="mul" dir="ltr" class="js-enabled">.
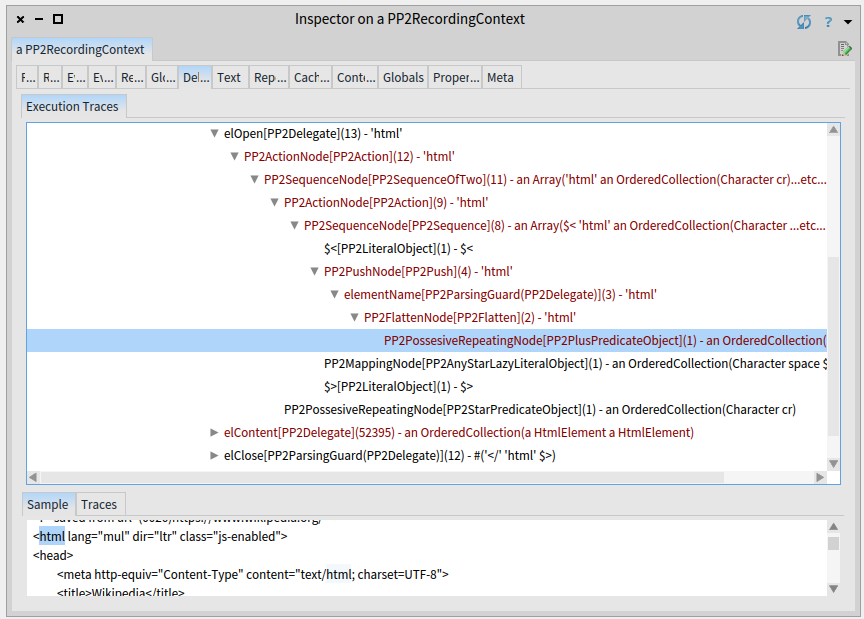
The html text (parsed by the elementName rule) has been recognized using only three invocation contrary to the eight invocations in the unoptimized case (see debug report of unptimized input).
In the unoptimized case (see the debug view of unoptimized elOpen) the html text is parsed so that one parser combinator was invoked for each of the characters.
In the optimized case (see the debug view of optimized elOpen) the whole html text is parsed by a single parser invocation.
Internally, the PetitParser transforms parser combinators into a while loop, which is much more efficient.
The same thing happened to the following mapping node, which consumes arguments of an openning tag. The PetitParser2 recognized an any-star-lazy pattern that, in this case, means to consume any character until end of the tag (i.e. >). This can be implemented as a single while loop saving 252 parser invocations.
Summary
Top-down parser combinators (such as PetitParser2) are popular because they are easy to understand, extend and debug. These advantages come at the price of low efficiency.
PetitParser2 offers optimizations that dramatically improve efficiency while preserving advantages of parser combinators.